Kami menggunakan cookies
Situs ini menggunakan cookies dari cmlabs untuk memberikan dan meningkatkan kualitas layanannya serta menganalisis lalu lintas..
Kami menggunakan cookies
Situs ini menggunakan cookies dari cmlabs untuk memberikan dan meningkatkan kualitas layanannya serta menganalisis lalu lintas..
LAYANAN CMLABS DALAM ANGKA, DARI 2019 SEKARANG
Total Engagement
Total Reach
Konten Diproduksi
Avg Keyword Rank
PERIKSA KESEHATAN WEBSITE ANDA, GRATIS & TIDAK TERBATAS
Halo! Sudah siap cobain cmlabs Web Analyzer? Don't worry, tool ini gratis! Namun saat ini, versi pertama dari fitur ini hanya tersedia di versi desktop. Jadi.. bersiaplah untuk menjelajahi dunia SEO yang lebih luas! Oh ya, jangan lupa mencoba cmlabs SEO Tool lainnya yang juga tersedia di web. Selamat mencoba!
cmlabs adalah sebuah Agensi SEO global yang menyediakan layanannya di Indonesia. Kami membantu bisnis mencapai visibilitas optimal di halaman hasil mesin pencari (SERP). Dengan strategi optimasi yang terfokus dan solusi pemasaran digital secara nyata, kami siap memandu Anda meningkatkan otoritas dan online presence bisnis secara berkelanjutan.
Selamat
Hari Raya Waisak



Baik bisnis Anda sedang di tahap awal atau tengah melakukan transformasi digital, cmlabs siap membantu menghadapi tantangan pemasaran Anda. Temukan audiens yang sedang mencari brand Anda di Google, sekarang!

SEO yang tepat membantu pencapaian berbagai OKR perusahaan

Ini saatnya Anda menjadi pionir dalam industri.

Optimalkan potensi brand dengan ekosistem digital yang kuat.

Jadi inspirasi kepercayaan pelanggan terhadap brand Anda.

Cari prospek klien baru sepanjang waktu, setiap hari dalam seminggu.

Hentikan pencarian pelanggan dengan cara kuno.

Ini saatnya Anda menjadi pionir dalam industri.

Optimalkan potensi brand dengan ekosistem digital yang kuat.

Jadi inspirasi kepercayaan pelanggan terhadap brand Anda.

Cari prospek klien baru sepanjang waktu, setiap hari dalam seminggu.

Hentikan pencarian pelanggan dengan cara kuno.

Jelajahi potensi perusahaan Anda dengan layanan SEO premium dari cmlabs. Gabungan strategi terbaru, analisis mendalam, dan solusi yang dipersonalisasi untuk mendorong pertumbuhan bisnis dalam mendominasi industri.

Tingkatkan bisnis Anda dengan Penulisan SEO profesional cmlabs dalam membuat konten yang menarik dan dioptimasi dengan kata kunci untuk menarik perhatian audiens serta meningkatkan ranking.

Tingkatkan otoritas online perusahaan Anda dengan layanan backlink blogger premium cmlabs. Dapatkan backlink berkualitas dari blogger berpengaruh untuk mendatangkan trafik berkualitas ke website Anda.

Perkuat kehadiran online perusahaan Anda dengan layanan online-publisher backlink terbaik kami. Dapatkan backlink otoritatif dari publisher ternama untuk meningkatkan visibilitas, kredibilitas, dan performa pencarian organik. Sebagai mitra media nasional terpercaya di Indonesia, kami berpengalaman dalam menyediakan layanan backlink. Dengan analisis cermat di setiap level, kami menjamin kualitas dan profesionalitas layanan untuk klien kami, hingga memperoleh kepercayaan dan kepuasan.
Jelajahi potensi perusahaan Anda dengan layanan SEO premium dari cmlabs. Gabungan strategi terbaru, analisis mendalam, dan solusi yang dipersonalisasi untuk mendorong pertumbuhan bisnis dalam mendominasi industri.
Tingkatkan bisnis Anda dengan Penulisan SEO profesional cmlabs dalam membuat konten yang menarik dan dioptimasi dengan kata kunci untuk menarik perhatian audiens serta meningkatkan ranking.
Tingkatkan otoritas online perusahaan Anda dengan layanan backlink blogger premium cmlabs. Dapatkan backlink berkualitas dari blogger berpengaruh untuk mendatangkan trafik berkualitas ke website Anda.
Perkuat kehadiran online perusahaan Anda dengan layanan online-publisher backlink terbaik kami. Dapatkan backlink otoritatif dari publisher ternama untuk meningkatkan visibilitas, kredibilitas, dan performa pencarian organik. Sebagai mitra media nasional terpercaya di Indonesia, kami berpengalaman dalam menyediakan layanan backlink. Dengan analisis cermat di setiap level, kami menjamin kualitas dan profesionalitas layanan untuk klien kami, hingga memperoleh kepercayaan dan kepuasan.

Teknologi terbaru kami untuk memproyeksikan traffic website.
Coba Proyeksi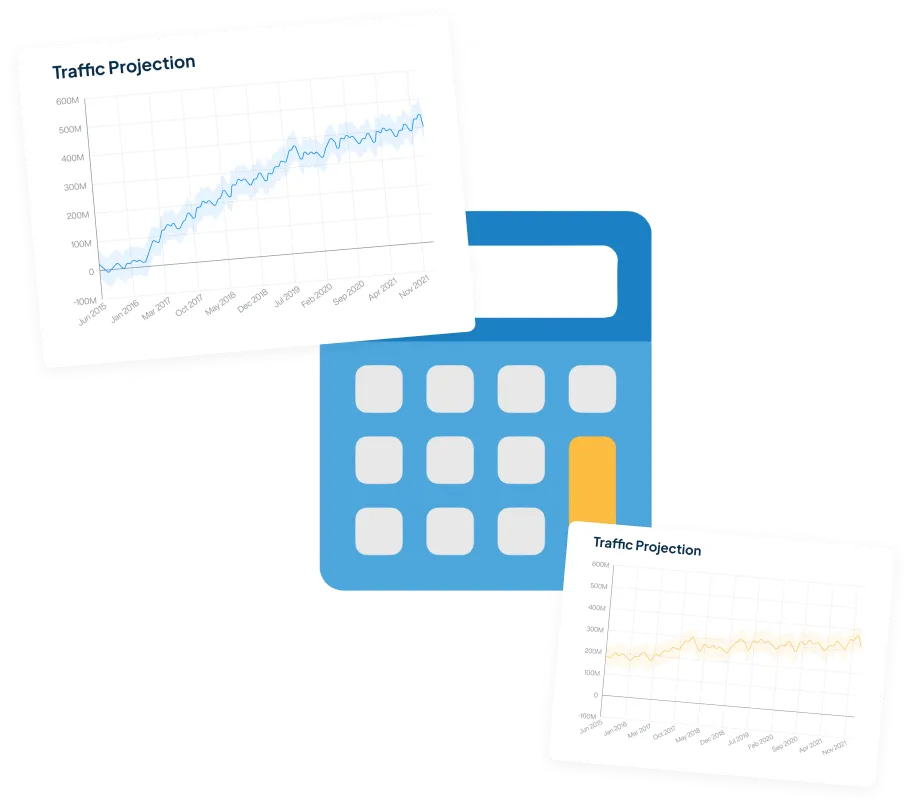
Jasa SEO dan Jasa Penulisan Konten SEO cmlabs dapat diakses oleh seluruh perusahaan dari negara di bawah ini. SEO Tools kami juga tersedia untuk semua pengguna tanpa batas wilayah, dan yang terpenting adalah SEO Tools kami gratis. Pastikan jangkauan pasar bisnis Anda luas, bersama jasa SEO cmlabs.

















