Google Updates All Information on Crawler Documentation

Google has just updated the information about its crawler and divided the discussion into various separate pages for more detail. Check it out here!




Key Takeaways
-
Google has just updated the information about its crawler and divided the discussion into various separate pages.
-
The purpose of this update is to provide a more comprehensive explanation of the crawler bot and the products affected.
-
Additionally, Google has also provided the latest information on the user agent string from GoogleProducer, content encoding, and the migration of JavaScript guidelines from the blog to the documentation.
In a significant update, Google has enhanced its crawler documentation, now featuring additional details and reorganized content into three distinct sections, each focusing more specifically on the topic.
Previously, the documentation was consolidated into a single page that encompassed all aspects of crawler functionality.
With this latest revision, Google has separated the information and introduced new sections that clarify the products impacted by each crawler and provide guidance on using the user agent token. This update aims to deepen the understanding of all aspects related to crawler pages.
What’s Changed in the Crawler Documentation?
Google has added two new sections across all crawlers: the impacted products and examples of robots.txt groups. Below is a screenshot showing the addition of these two new sections in Google’s crawler documentation:
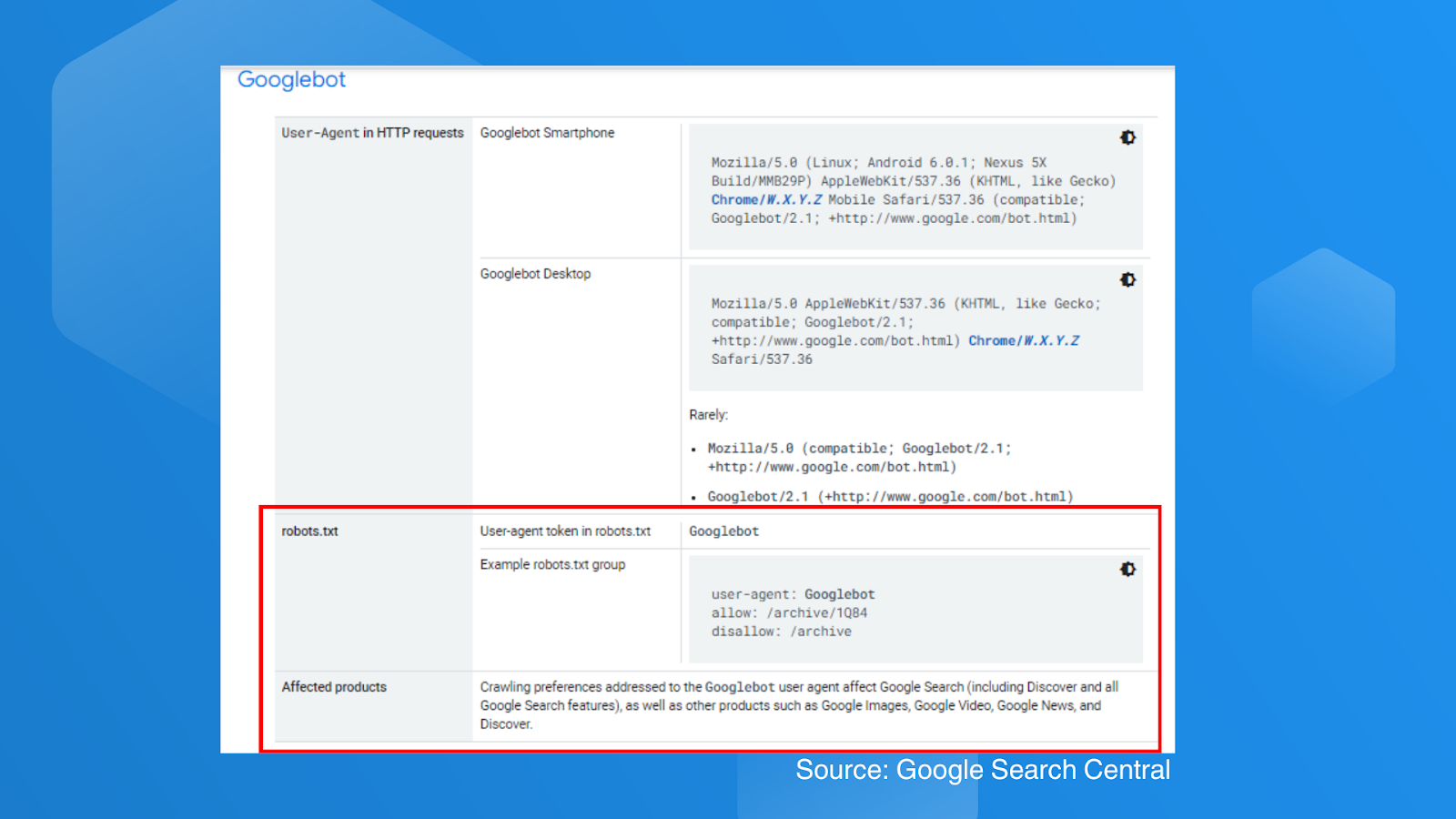
Google stated that the reason for updating this information is the length of the discussion, which limited their ability to add new information about their crawlers.
Additionally, in the changelog, Google noted that they have added several pieces of information, including updates to the HTTP user agent string from GoogleProducer, new content encoding information, and the migration of JavaScript guidelines from the blog to the documentation, allowing users to study the guidelines more freely.
Google's General Crawler and Its Impact on Google Products
Google's documentation for the general crawler explains the user agent string in HTTP requests, the user agent token for the User-agent: line in robots.txt, and the Google products affected by crawling preferences.
Google also clarifies that some crawlers have more than one token, allowing users to match just one token to qualify.
Here are the details of the crawler list along with the affected products:
- Googlebot: This crawling preference affects Google Search, including all its features, Discover, Google Images, Google Video, and Google News.
- Googlebot Image: This crawling preference impacts Google Images, Discover, Google Video, and all Google Search features that include images, logos, and favicons.
- Googlebot Video: This preference affects Google Search features related to video and other products that depend on video.
- Googlebot News: This preference influences all Google News features, such as the News tab in Google Search and the Google News app.
- Google Storebot: This preference affects all Google Shopping features, including the Shopping tab in Google Search and Google Shopping.
- Google Inspection Tool: This preference impacts search testing tools like the Rich Result Test and URL inspection in Search Console. This crawler does not affect Google Search or other products.
- GoogleOther: This preference does not impact specific products, as it is a general crawler used to retrieve publicly accessible content from websites.
- GoogleOther-Image: Similar to GoogleOther, this crawler does not affect specific products. GoogleOther-Image is the version of GoogleOther used to fetch URLs of publicly uploaded images.
- GoogleOther-Video: Like GoogleOther, this crawler does not impact specific products. Its function is the same as GoogleOther-Image, but it retrieves video URLs.
- Google-CloudVertexBot: This crawler affects crawling requested by site owners to build Vertex AI Agents and does not impact Google Search or other products.
- Google-Extended: This crawler is an independent product token that website owners can use to manage whether their sites contribute to enhancing Gemini Apps and the generative Vertex AI API, including the upcoming model generations driving these products. This crawler does not affect site inclusion or ranking in search results.
Crawlers for Special Cases by Google and Their Impact on Products
In addition to general crawlers, Google also explains crawlers for special cases and their impact on products, which can be summarized as follows:
- APIs-Google: This crawler affects push notification messages from Google APIs.
- AdsBot Mobile Web: This crawler influences Google Ads' ability to assess the quality of ads on a webpage.
- AdsBot: This preference has the same impact as AdsBot Mobile Web.
- AdSense: This preference affects Google AdSense, where its crawler visits participating sites to provide relevant ads.
- Google-Safety: The user agent Google-Safety is responsible for searches specifically aimed at identifying abuse, such as discovering malware in links posted publicly on Google properties. Thus, its usage is not affected by search preferences.
List of User-Triggered Fetchers by Google
Another page added by Google as part of the crawler documentation update is dedicated to user-triggered fetchers. This page discusses bots activated by user requests to perform fetching functions within Google products, along with a list of these bots.
Here is the list of user-triggered fetchers and their associated products:
- Feedfetcher: This bot is used to crawl RSS or Atom feeds for Google News and PubSubHubbub.
- Google Publisher Center: This bot retrieves and processes feeds explicitly provided by publishers on the Google News landing page.
- Google Read Aloud: This bot fetches and reads web pages using text-to-speech (TTS) based on user requests.
- Google Site Verifier: This bot retrieves verification tokens from Search Console.
The changes and additional information made by Google for each of its crawlers have made the content more comprehensive. This allows you to understand how these crawlers impact various aspects of Google, even if not all of them have a direct influence.
News Source
As a dedicated news provider, we are committed to accuracy and reliability. We go the extra mile by attaching credible sources to support the data and information we present.
- Google Search Central (common crawlers) - https://developers.google.com/search/docs/crawling-indexing/google-common-crawlers
- Google Search Central (special-case crawlers) - https://developers.google.com/search/docs/crawling-indexing/google-special-case-crawlers
- Google Search Central (user-triggered fetchers) - https://developers.google.com/search/docs/crawling-indexing/google-user-triggered-fetchers
- Google Search Central (latest documentation updates) - https://developers.google.com/search/updates#reorganizing-the-crawler-documentation

Alivia Ariatna
As an experienced SEO content writer, I specialize in crafting compelling, keyword-optimized content with extensive research on it. I stay updated with the latest SEO trends and best practices to ensure my content meets both user intent and search engine requirements.
Another post from Alivia

Is ChatGPT Perceptive to Indonesian Writing Rules? A Study
Thu 30 Jan 2025, 08:55am GMT + 7
Google Releases Documentation on Google Trends Guide
Mon 04 Nov 2024, 08:22am GMT + 7
Google to Remove Sitelink Search Box by November 21, 2024
Fri 01 Nov 2024, 08:39am GMT + 7
Google Wins Nobel for AI Research, Sparks Debate in AI Field
Wed 16 Oct 2024, 11:42am GMT + 7More from cmlabs News your daily dose of SEO knowledge booster
In the development of its latest search engine, Bing has partnered with GPT-4 to deliver the most advanced search experience. Here are the details.
Bard, an experimental conversational AI service, combines information with language model intelligence. Check out the details here.
With the rapid advancement of AI technology, major search engines like Google and Bing are now equipped with their respective generative AI. Here is the detail.
WRITE YOUR COMMENT
You must login to comment
All Comments (0)
Sort By